本記事の原文はもともとNutanix社のStaff Solution Architectで、Nutanix Platform Expert (NPX) #001、
そしてVMware Certified Design Expert (VCDX) #90として活動しているJosh Odger氏によるものです。
原文を参照したい方はNutanix Resiliency – Part 7 – Read & Write I/O during Hypervisor upgradesをご確認ください。
情報は原文の投稿時のままの情報ですので、現時点では投稿時の情報と製品とで差異が出ている場合があります。
当社のNutanix社製品についてはこちら。本ブログのNutanix関連記事のまとめページはこちら。
ネットワールドのNutanix関連情報は、ぜひ当社のポータルから取得ください。
(初回はID、パスワードの取得が必要です)
まだパート1~4を読んでいない場合は前述したパートでは重要なRFと障害からの復旧スピード、RF2から3へ変更する事での回復性能の向上、同じくEC-Xを利用し同じRFを提供しながらの容量削減を記載していますので是非みてください。
パート5,6ではCVMがメンテナンスまたは障害時にどの様にリード・ライトI/Oを行うかを説明し、このパート7ではリード・ライト I/Oがあるハイパーバイザ(ESXi,Hyper-v,XenServer,AHV)のアップグレードにどの様な影響があるかを見てみます。
このブログはパート5,6と深く関係していますのでパート5,6を完全に理解して頂くことをお奨めします。
パート5,6を読むことで,CVMがどんな状況になったとしてもリード、ライト I/Oは継続され設定しているRFに従いデータが保持されるという事が解ります。
ハイパーバイザのアップグレードイベントで仮想マシンはまず移行され通常の操作が継続されます。
ハイパーバイザの障害では仮想マシンはHAのにより再起動され他のノードで稼働します。
ハイパーバイザまたはノードの障害なのか、ハイパーバイザのアップグレードなのか
どちらにしても結果的には仮想マシンはほかのノードで稼働し、元のノード(下のダイアグラムでいうNode1)はある程度の期間オフラインとなりローカルディスクは利用できなくなります。
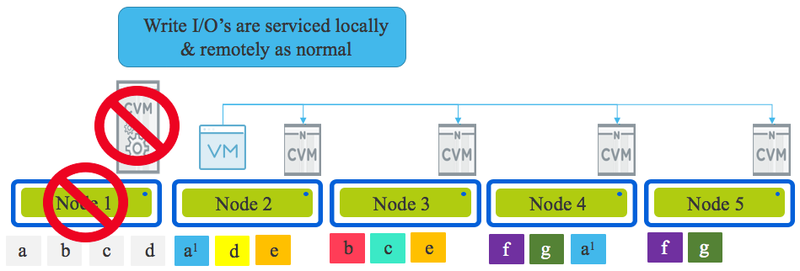
リードI/Oのシナリオはどうでしょうか?パート5で説明した内容と同じでリードはリモートのデータを読みに行くか仮想マシンの移動先のノードに複製データがある場合、リードはローカルからとなります。
リモートに1MBのエクステントがローカライズされるとその後のリードはローカルとなります。
書込みはどうか?パート6であるように
書き込みは常に構成されたRFに順次し、たとえハイパーバイザのアップグレード、CVM、ハイパーバイザ、ノード、ネットワーク、ディスク、SSD障害がだとしても一つの複製とローカルへ残りの1つまたは2つの複製をクラスタの現在のパフォーマンス、ノードの使用量をベースに分散します。
それは本当にシンプルでこのレベルの回復性能を実現するのはADSFのおかげなのです。
Summary:
- A hypervisor failure never impacts the write path of ADSF
- Data integrity is ALWAYS maintained even in the event of a hypervisor (node) failure
- A hypervisor upgrade is completed without disruption to the read/write path
- Reads continue to be served either locally or remotely regardless of upgrades, maintenance or failure
- During hypervisor failures, Data Locality is maintained with writes always keeping one copy locally where the VM resides for optimal read/write performance during upgrades/failure scenarios.
記事担当者 : SI技術本部 カッシー @Nutanix_NTNX