本記事の原文はもともとNutanix社のStaff Solution Architectで、Nutanix Platform Expert (NPX) #001、
そしてVMware Certified Design Expert (VCDX) #90として活動しているJosh Odger氏によるものです。
原文を参照したい方はNutanix Resiliency – Part 1 – Node failure rebuild performanceをご確認ください。
情報は原文の投稿時のままの情報ですので、現時点では投稿時の情報と製品とで差異が出ている場合があります。
当社のNutanix社製品についてはこちら。本ブログのNutanix関連記事のまとめページはこちら。
ネットワールドのNutanix関連情報は、ぜひ当社のポータルから取得ください。
(初回はID、パスワードの取得が必要です)
2013年の中旬からNutanixでビジネスクリティカルアプリケーション、スケーラビリティ、回復力とパフォーマンスに注目しながら働いてきています。
私はよくお客様やパートナーの方とNutanix製品の回復力に関する事やNutanix Platformでどのように構成するのが一番良い方法か会話しています。
Nutanix Platformの数多くある強みの一つで私が多くの時間と努力を費やしてきた領域は回復力とデータの完全性、そして重要なのは障害シナリオとどのようにNutanixが障害時に動作するのかを理解する事です。
Nutanixは独自の分散ストレージファブリック(ADSF)で仮想マシン、コンテナのストレージの提供をします。そのRF2 または3で構成されている物理サーバでもあります。
単純な視点からRF2とN+1(例えばRAID5)RF3 とN+2 (例えばRAID6)を比較する事が出来ますが、RF2と3は分散ストレージファブリックの障害からの素早く再構築が出来き、障害発生の前に検知し解決するディスクスクラブにより回復力が従来のRAIDよりも非常に高いのです。
Nutanixはデータの完全性を確実にするための継続的なバックグラウンドでのスクラブの実施だけでなく、すべてのリード、ライトへチェックサムの実施をしています。
RF2が使われいるとしてもADSFの回復力の話をするときの重要な要素はRF2または3に準拠した形でドライブ、ノードフェイルに対する復旧のスピードです
リビルドはすべてのノード、ドライブをまたいだ完全な分散処理になるので、素早く、各ノードのボトルネックを最小減に抑え、稼働しているワークロードのインパクトを少なくすることが出来るのです。
どうして早いか? 当然、CPU世代、とネットワーク接続性、同様にクラスタのサイズ、どのようなドライブが搭載されているか(NVMe , SATA-SSD , DAS-sATA)に依存します。サンプルはこうです。
テスト環境が16クラスタ 殆どが五年前のハードウェアのNX-6050 , NX-3050の混在構成でCPUはIvy Bridge 2560( 2013年Q3のもの)、各ドライブは6本のSATA-SSDを搭載し2x10GBのネットワーク接続とします
最初のテストではデータ削減技術(重複排除や圧縮またはいれージャーコーディング)を利用しないデータを利用しますが、データ削減がパフォーマンスを向上しデータ削減によりデータの再構築にかける時間を短縮できるので、このテストの結果はベストなケースシナリオではありません。
次に示す通りノードは5TBちょっとのデータがあり、測定するのは5TBのノード障害シナリオに対するリビルドの速度となります。
クラスタの半分のノードは約9TBの容量で他の半分は1.4TB ~ 3TBの容量となります。
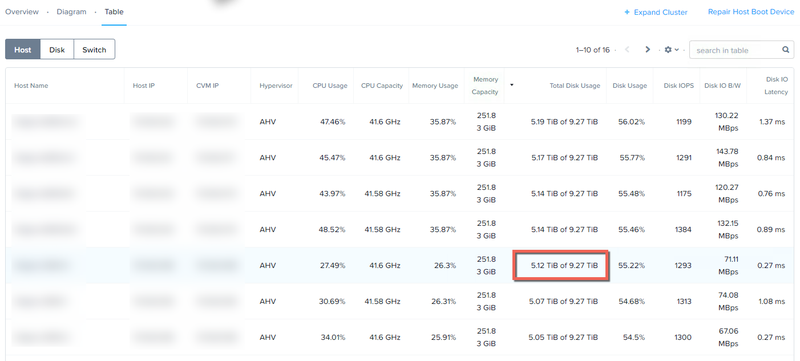
ノード障害はIPMIの”Power off server - immediate” にて実施します。
この操作は電源を引き抜く操作に相当します。
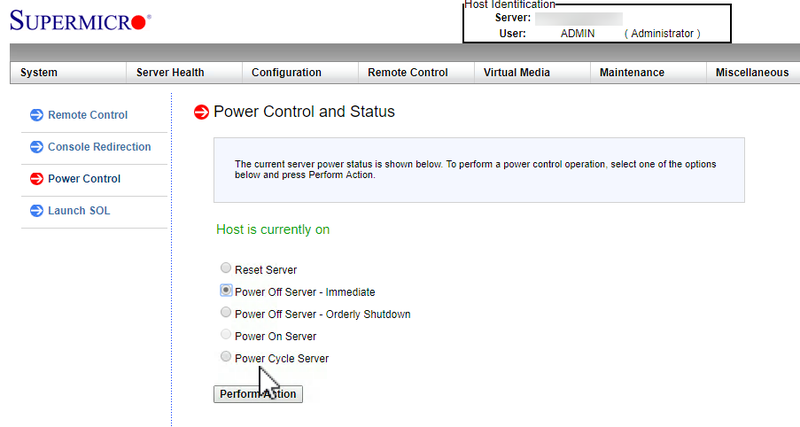
Acropolis Distributed Storage Fabric (ADSF)の回復力の良いところはノード障害中の各ノードの統計情報を見ると明らかにわかります。1GBpsのスループットがシングルノードで達成しクラスタのすべてのノードが容量に応じてほぼ同じスループットが出ているのがわかります。
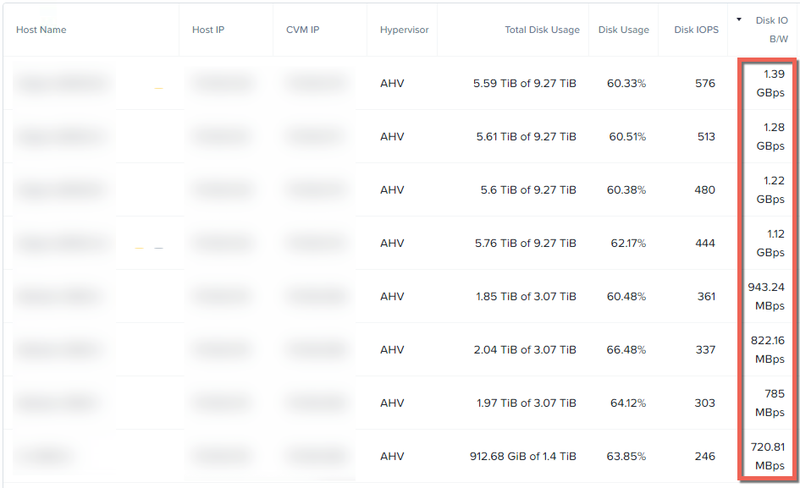
半分のノードのスループットが低いのは容量が少なく、結果リビルドするデータが少ないからです。
もしすべてのノードが同じだったとしたらスループットは概ね最初の4つのリストにあ
RAIDに組まれているドライブが大きくなればなるほど、リビルドにかかる時間が多くなり、その間の障害発生に対しるデータロスのリスクが高くなります。
RAIDのリビルド中に発生するパフォーマンスの影響もドライブ一台の障害と一台のリビルド先しかないことかにより高くなります。
これは長いウィンドウのパフォーマンスインパクトとデータが保護されていない事を意味します。
るノード(1GBpsでているもの)と同じになるでしょう。
Nutanixが分散ストレージファブリックを使っていなければ、リビルドはリビルド元、RAID、または一般的なHCIのリビルド先のノードによって制約が発生するでしょう。
例えば、全てのノードが小さいエクステント(1MB)を多対多、効率的にクラスタ内で複製する事に反して、Node-Aは大きいオブジェクトをNode-Bへ複製するでしょう
これまでのRAID5を比較すると、リビルド元になるのは障害が発生した特定のドライブのみとなります。RAIDのドライブは3~24で構成されリビルド用に一つのスペアディスクを設定します。つまりリビルド操作は一つのディスクによるボトルネックがあります。
ほとんどすべてのITプロフェッショナルの方々はRAID5、たとえRAID6であったとしても 数時間から数日の長期間にわたるシングルドライブ障害の復旧にかかるRAID構成に対して“ゾッ”とする話をもっています。
これらの一般的な嫌な経験はN+1(そしてRF2)でさえ悪評となった大きな理由です。
RAID5 , 6のリビルドが数分以内で完了できたとしたら・・
大多数の次に発生する障害がダウンタイムやデータロスをもたらす結果にはならないでしょう。
ではNutanix ADSFのリビルドパフォーマンスにもどりましょう。
繰り返しですがADSFはレプリカ(データ)を1MBのサイズでクラスタ内に分散します。(すべてのデータが2つだけのノードに存在するペアスタイルではありません)
この分散がリビルド中の書込みのパフォーマンスを向上し、結果的に多くのコントローラー、CPU、ネットワーク幅をリビルドのために利用します。
簡単に言うと、クラスタが大きくなればなるほど、ノードはレプリカのRead, Writeが増えていき復旧にかかる時間が早くなります。
クラスタのサイズが大きいほど障害とリビルドに対するインパクトが下がり、大きなクラスタではRF2の構成でさえ素晴らしい回復力を提供できるのです。
下の画像はNutanixのPrismから取得した分析のスクリーンショットです。
ノード障害を想定してからのリビルド期間中のストレージプールのスループットを表示しています。
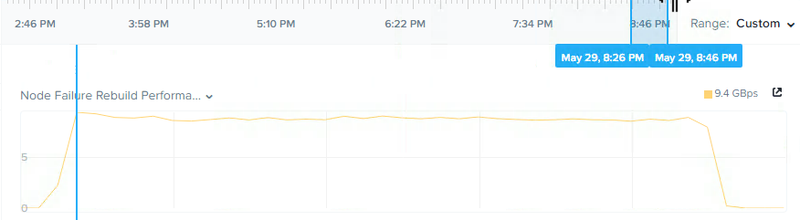
このチャートではリビルドが20:26にそして終了したのは20:46で完了までの間 9GBpsを維持している事がわかります。
この例では5年前のノードで5TBの利用率でデータの完全なリストアに20分以下となるのです。
クラスタサイズが増えるか 新しいノードが速いNICやNVMeドライブのようなストレージを使われているのであれば、リビルドはもっと早くなりRF2を利用していてもデータロスの可能性はとても少なくなるのです。
NutanixではCVMでデータ保護をしているのでノードが増えても処理できるマシンが増えリビルドにかかる時間は減りますし、早いCPU等を搭載したモデルでもリビルドにかかる時間が削減されます。
イメージ的にはRAIDコントローラ処理速度もOne-Clickで!といったところですね!
Summary:
- Nutanix RF2 is vastly more resilient than RAID5 (or N+1) style architectures
- ADSF performs continual disk scrubbing to detect and resolve underlying issues before they can cause data integrity issues
- Rebuilds from drive or node failures are an efficient distributed operation using all drives and nodes in a cluster
- A recovery from a >5TB node failure (in this case, the equivalent of 6 concurrent SSD failures) can be less than 20mins
Next let’s discuss how to convert from RF2 to RF3 and how fast this compliance task can complete.
記事担当者 : SI技術本部 カッシー @Nutanix_NTNX