本記事の原文はもともとNutanix社のStaff Solution Architectで、Nutanix Platform Expert (NPX) #001、
そしてVMware Certified Design Expert (VCDX) #90として活動しているJosh Odger氏によるものです。
原文を参照したい方はNutanix Resiliency – Part 9 – Self healingをご確認ください。
情報は原文の投稿時のままの情報ですので、現時点では投稿時の情報と製品とで差異が出ている場合があります。
当社のNutanix社製品についてはこちら。本ブログのNutanix関連記事のまとめページはこちら。
ネットワールドのNutanix関連情報は、ぜひ当社のポータルから取得ください。
(初回はID、パスワードの取得が必要です)
Nutanixには他の従来のSAN/NASアレイだけでなく他のHCI製品とは異なる極めて重要で独自性のある自己回復機能があります.
Nutanixは完全自動でSSDs/HDDs/NVMeやノード障害時だけでなくユーザ処理を介さないで管理スタック(Prism)を完全に復旧させます。まず、デバイス,ノード障害からの自己修復を行いましょう。
簡単に平均の8ノード※のNutanixクラスタと従来のデュアルコントローラSANを比較してみましょう
※ここでいう平均とはグローバルに販売されているノードの平均を計算しています。
一つのコントローラー障害が発生するとSAN/NASは復旧機能が無い状態となり、復旧能力が回復する前にベンダーがコンポーネントを交換するSLAを受けることになります。
それと比べてNutanixは8つのコントローラーの内の1つ(12.5%)がオフラインとなり、残された7つのコントローラーはワークロードを継続して提供し自動的に回復能力をパート1で示したように数分で復旧します。
私が以前ブログで 書いたHardware support contracts & why 24×7 4 hour onsite should no longer be required ではもっと詳細に本内容カバーしています。
簡単に言うとプラットフォームの回復性能を復旧するのは新しいパーツの到着、さらに技術人員による操作、ダウンタイム、データロスの危険性は自己修復がハードウェアの交換、人による介入を無しに完全に復旧できるプラットフォームと比較して極めて高いのです。
より小さいクラスタならどうなの?と思う人もいると思います。
いい質問です、たとえ4ノードのクラスタで1ノードの障害が発生してもハードウェアの交換や人手を介さないで完全に自己修復機能が3ノードでクラスタを稼働するようにします。
Nutanix環境でノード障害が発生した際に完全に自己修復できない唯一の構成は3ノードクラスタです。
しかし3ノードクラスタでも1ノード障害まで耐えられます、データは再保護されクラスタの機能は2ノードであっても機能しますが、次の障害でダウンタイムは発生しますが致命的なデータロスは起こりません。
2ノードで稼働していたとしてもドライブ障害には耐えられるのです。
3ノードのvSANクラスタで1ノード障害が発生するとデータは再保護されずにノードが交換され、リビルドが完了するまでリスクは継続します。
Nutanixがデータ(管理スタックのPRISM)の自己修復を行える前提条件はストレージが十分にあるかだけです。
どのくらいのキャパシティがあるかを確認し、N+1のRF2 , N+2 の為のRF3構成を推奨します。これは2台の障害または、一台の障害の後に発生する後続の障害に対応します。
そのため最小構成クラスタでのシナリオではRF2では33% , 5ノードの場合で40%となります。しかし、競合他社による不確実性、疑問性の打破の前にクラスタサイズが増える際に自己修復でどの程度の容量が必要となるかを見てみましょう。
次のテーブルはN+1とN+2を基準にクラスタのノードが32ノードまで拡張するための自己修復に必要な容量となります。
ノート:これらの値は全てのノードが100%利用している際の状態となります。
実際はこれよりもこの表よりも低いのが現状です。
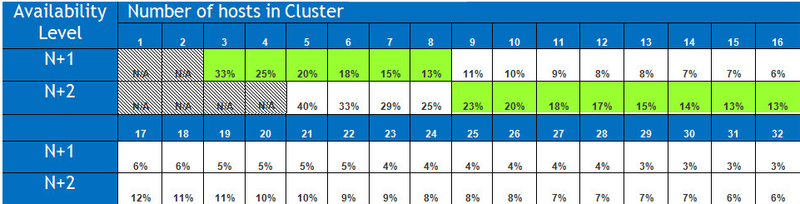
8ノードクラスタを見てみると容量はちょうど13%が必要となります。
N+2を8ノードで構成し2重障害時に完全にリビルドし回復性を復旧するには25%です。
重要なのは、Nutanixは1MBのエクステントをクラスタ内で分散し使用するADSFのおかげで空き容量は大きなオブジェクト(例:256GB)を必要としないという事です。
このため、他のプラットフォームと異なりフラグメンテーションによる容量の無駄が無いのです。
ノート:クラスタ内のノード数はリビルドの容量に影響はありません。
ADSFのいくつかの利点としてNutanixはドライブキャッシュはディスクグループのコンセプトを持っていない事です。
ディスクグループは一つのキャシュドライブの障害がディスクグループ(複数のドライブ)をオフラインにし必要以上にリビルド処理を強制的に実施することになるため、回復性能(レジリエンシー)に対して高いリスクとなります。
ADSFのドライブ障害はただの障害で、一つのドライブ障害はそのドライブに乗っているデータの再構築が必要となり、その処理は1対1の他のプロダクトとは異なり、多対多の分散処理となるのです。
一つのSSDドライブが搭載しているNutanixでSSDドライブが障害になったときだけがノード障害と同一となるのですが、これはADSFの制限ではなく、どのハードウェアを利用するかによります。
本番環境化では2つのSSDの回復性能(レジリエンシー)が追加コストより上回るので、一つのSSDモデルよりも2つのSSD搭載モデルを推奨します。
興味深い所:vSANはおそらく一つのSSDシステムがディスクグループの一つのキャッシュとなっている以上、常にこれが単一障害点となります。
クラスタの自己修復と他の障害が発生した際はどのようになるか?とよく質問されます。
2013年にシドニーのvForumでNutanixとこのセッションをプレゼンしており、内容をカバーしています。
このセッションはスタンディングルームでしたが、人気であったので5ノードクラスタでノード障害時に4ノードクラスタのためにどのように自己修復が行われるか、たの障害で3ノードクラスタになるためのどのように自己修復が行われるかのブログを書きました。
これは新しい機能でもなく、他の最新のプラットフォームと比べて最も回復性能が高いアーキテクチャでもありません。
Scale Out Shared Nothing Architecture Resiliency by Nutanix
ディスクグループとして構成されている障害時に実施する事は最近の“vSan degraded device handling“で投稿されているVMware vSAN 記事から解るように障害の為により多くのディスクスペースを確保する必要がある事です。
この記事からいえる2つの考慮する事は
〇25-30%の余裕のある空き容量をクラスタ内で常に確保しなければいけないという事
〇ドライブがキャッシュだった場合にディスクグループはオフラインとなる事です。
vSANのアーキテクチャを考慮した際に何故VMwareが25~30%の空き容量に加えて FTT2 (three copies of data)を推奨するかが論理的にわかるようになります。
Next let’s go through the self healing of the Management stack from node failures.
ではノード障害の管理スタックの自己修復に移りましょう
Nutanixの全てのコンポーネント、構成、管理、監視、拡張と自動化はクラスタ内のすべてのノードで完全に分散されるようになります。
コアな機能を利用するためにお客様が管理コンポーネントを展開する必要はありません。
お客様が管理スタックを冗長化する必要もありません。
結果、Nutanix/Acropolisの管理層には単一障害点が無いのです。
下のではそれぞれのノードでサービスをしている4つのCVMがいます。
クラスタ内では一つのAcropolis Masterと複数のそれに所属するSlaveが存在ます。

Acropolis Masterが利用不可となった場合は他のAcropolis SlaveがMasterへ昇格します。
これはADSFによって完全分散されたストレージ内にCasandra databaseが保存されているために達成できるのです。
新しくノードがクラスタに追加された場合は、Acropolis Slaveが追加されクラスタの管理層が分散され、結果的には管理が問題になる事はないのです。
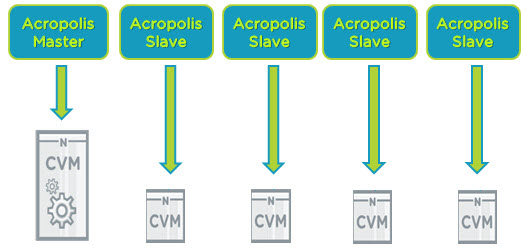
パフォーマンス管理、統計集計、仮想マシンのコンソール接続はMasterまたは、Slaveが提供している管理タスクのほんの一部なのです。
これに加えて他のNutanix利点は管理層はサイジング、手動で拡張する必要が一切無いのです。 vAppやDatabase サーバ、Windows仮想マシンの展開、インストール、構成、管理やライセンスが不要です。これにより管理環境を単純化しコストも削減できるようになります。
Key point:
- The Nutanix Acropolis Management stack is automatically scaled as nodes are added to the cluster, therefore increasing consistency , resiliency, performance and eliminating potential for architectural (sizing) errors which may impact manageability.
The reason I’m highlighting a competitors product is because it’s important for customers to understand the underlying differences especially when it comes to critical factors such as resiliency for both the data and management layers.
Summary:
Nutanix ADSF provides excellent self healing capabilities without the requirement for hardware replacement for both the data and management planes and only requires the bare minimum capacity overheads to do so.
If a vendor led with any of the below statements (all true of vSAN), I bet the conversation would come to an abrupt halt.
- A single SSD is a single point of failure and causes multiple drives to concurrently go offline and we need to rebuild all that data
- We strongly recommend keeping 25-30% free “slack space” capacity in the cluster
- Rebuilds are a slow, One to One operation and in some cases do not start for 60 mins.
- In the event of a node failure in a three node vSAN cluster, data is not re-protected and remains at risk until the node is replaced AND the rebuild is complete.
When choosing a HCI product, consider it’s self healing capabilities for both the data and management layers as both are critical to the resiliency of your infrastructure. Don’t put yourself at risk of downtime by being dependant on hardware replacements being delivered in a timely manner. We’ve all experienced or at least heard of horror stories where vendor HW replacement SLAs have not been met due to parts not being available, so be smart, choose a platform which minimises risk by fully self healing.
記事担当者 : SI技術本部 カッシー @Nutanix_NTNX